This post is about ditching Kafka in favor of ZeroMQ, based on a year-long experience of using Kafka for real-time log aggregation in a production setting of Auth0 Webtasks. What, why, and how - read on.
What is Auth0 Webtasks?
Auth0 Webtasks is a hosting platform for Node.js microservices. You can author a snippet of Node.js code, and deploy it in a jiffy to the cloud without worrying about the things that most hosting platforms make you worry about. In other words, all you need is code.
The problem: real-time logging
Real-time access to server-side logs is what makes backend development palatable in the era of cloud computing. As a developer you want to be able to get real-time feedback from your server side code deployed to the actual execution environment in the cloud, especially during active development or staging.
For example, given the following server side code hosted in Auth0 Webtasks:
module.exports = function (cb) {
console.log('A new request received at', new Date());
cb(null, 'Hello, world');
};
you want to be able see the logs generated by it in real time when that code is invoked in the cloud:
tj-mac:wt-cli tomek$ wt logs
[06:41:13.980Z] INFO wt: A new request received at Wed Sep 02 ...
And by real-time I don’t mean using FTP or a discrete HTTP call to fetch the latest logs. I also don’t mean a few seconds later. I mean streaming and real-time logs.
First approach: Kafka
This log aggregation and dissemination scenario sounds like a poster child use case for Kafka. Kafka is a message broker specialized for high-throughput, real-time messaging. It makes several design trade-offs that make it uniquely suited for log processing. Many successful large scale deployments use Kafka for that purpose, among them Netflix. It is a real pleasure to read about Kafka’s design. Very elegant and deep, scratches the metal where it needs to in order to provide the features that matter.
In case of Auth0 Webtasks, we have been using Kafka for over a year to consolidate logging information across several components within a CoreOS cluster running Docker containers. Arrows indicate the flow of log information in that design:
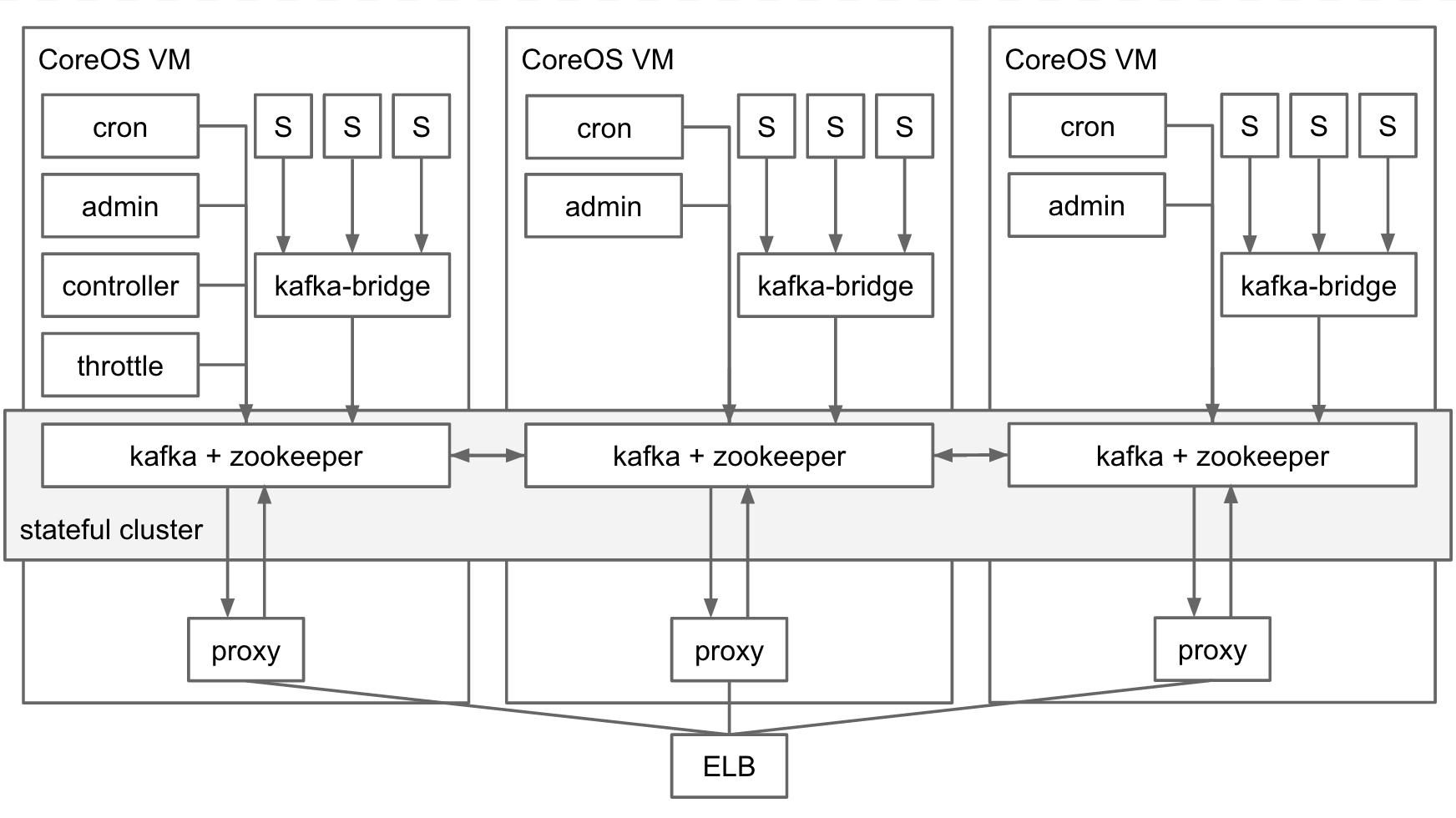
All logs are normalized into discrete bunyan records (JSON documents). They are published to Kafka under various topics, either system-wide or specific to the tenant provisioned in the multi-tenant webtask cluster. Streaming, real-time logs logs can be accessed over a long running HTTP request either in plaintext or in the text/event-stream encoding. The proxy component acts as a Kafka subscriber and implements protocol translation to HTTP. Functionally this solution served us very well, with performance leaving nothing to be desired given our workloads.
The problem with Kafka
At Auth0, high availability is the high order bit. We don’t stress as much about throughput or performance as we do about high availability. We don’t have a concept of a maintenance period. We need to be available 24/7, year round. Given the nature of some of our customers, if we are down, “babies will die”. This goal informs many of the design decisions, for example cross-cloud provider failover. It also applies to the design of the webtask cluster.
Kafka has been deployed in a high availability configuration, with one instance per CoreOS VM, and a replication factor of two. Kafka depends on Zookeeper for distributed configuration, and Zookeeper has been deployed in a similar fashion: one instance per CoreOS VM. In theory a cluster of 3 VMs should survive the loss of a single VM, and subsequent reinstatement of that VM back into the cluster. Such a situation is a typical failure or maintenance scenario one needs to plan for when hosting a service in AWS or elsewhere.
In practice we found setting up an HA deployment of Kafka and Zookeeper a never ending whack-a-mole exercise of chasing yet another corner case of failure recovery.
Over the year we have experienced several failures where the Kafka/Zookeeper combo struggled to rejoin the cluster after VM recycle, with a domino effect on the entire logging system.
I still like Kafka for its functional and performance characteristics, not to mention sheer elegance and clarity of design. But supporting an HA deployment of it, or getting to the point where it does not need a lot of ongoing support, proved to be more than we bargained for. Large companies like Netflix may be able to spend some serious engineering resources to address the problem or at least get it under control. Auth0 is a startup of about 40 people (as of this writing), all very talented individuals, yet most of them with more important things to do than babysitting Kafka.

After a year of running Kafka (sometimes at odd hours of the night) we’ve decided to have another hard look at the problem. We were ready for a metamorphosis.
New look at the problem
I’ve started by distilling our problem to the bare essentials: we wanted to aggregate and expose logging information in real-time. We did not care as much about supporting access to historical logs, something that is a benefit of using Kafka. I figured that if the problem of real-time log consolidation is solved, storing it for later inspection could be easily solved later as a layer on top. Divide & conquer.
Take two: ZeroMQ
At that point I started looking at ZeroMQ, a messaging library that implements several messaging patterns common in distributed applications. This includes the pub/sub pattern which matched our log aggregation scenario well.
A week later we had a working prototype based on ZeroMQ. Compare and contrast this picture with the design based on Kafka above:
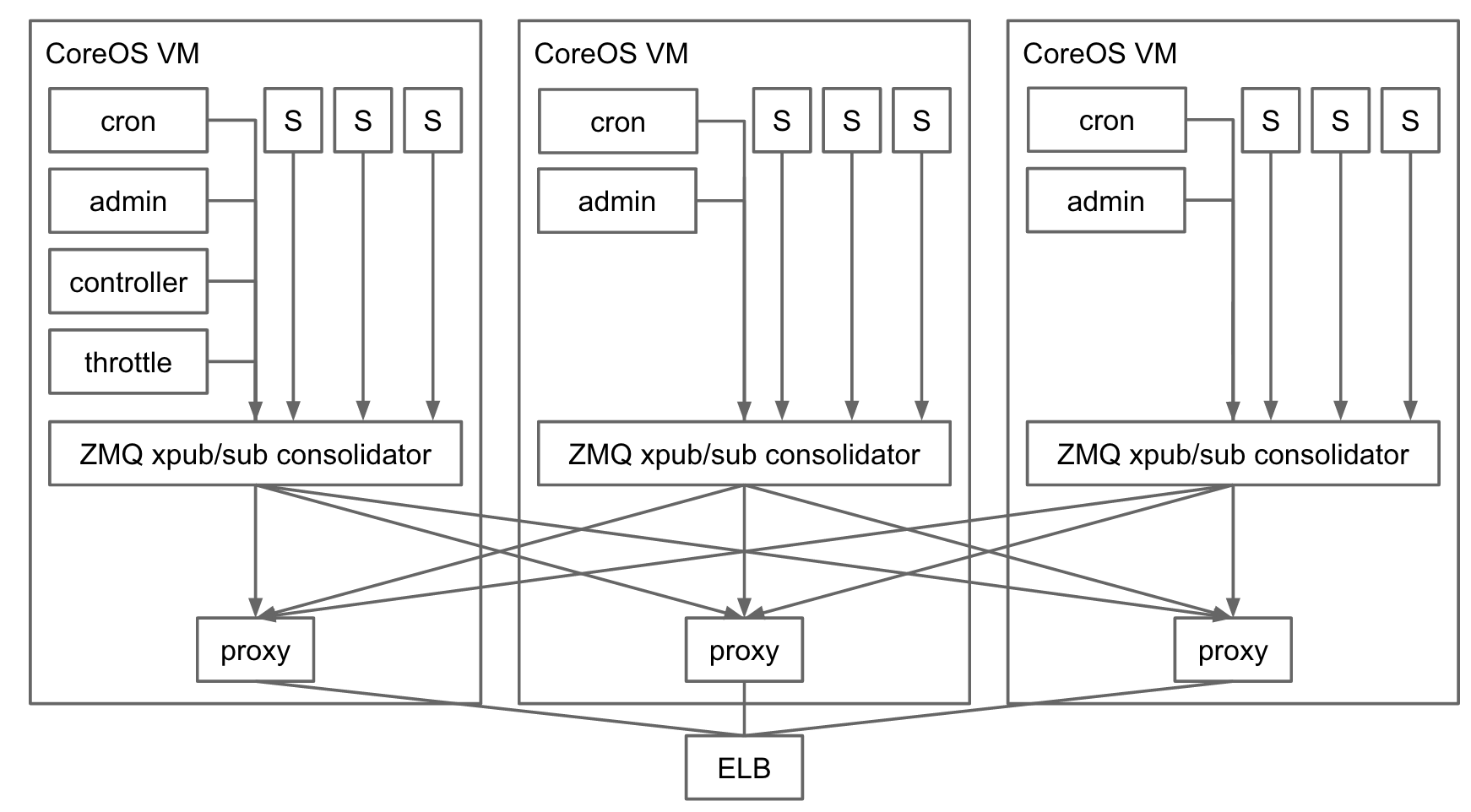
The key component is the ZeroMQ Consolidator running on each VM in the cluster. Its job is to consolidate logs from all components running on that VM, and make them available for downstream subscribers. The consolidator exposes the xpub ZeroMQ endpoint. All processes running on the machine connect to it using ZeroMQ’s pub socket type to publish log messages. The consolidator also exposes the xsub endpoint, which components interested in processing streaming logs connect to. Consolidator acts as a simple in-memory pump between the xpub and xsub sockets.
You can see a bare-bone example of using xpub/xsub ZeroMQ sockets that way in this Node.js code snippet.
In case of Auth0 webtasks, streaming real time logs are exposed over long running HTTP requests. Every time an HTTP request for streaming logs arrives, the proxy component on the diagram above creates a ZeroMQ sub socket and connects it to the xsub endpoints on each of the VMs in the cluster (discovered through etcd). It then acts as a message pump and a protocol translation layer between ZeroMQ messages and the long running HTTP response.
Kafka vs ZeroMQ
Generally speaking comparing Kafka to ZeroMQ is like comparing apples to oranges, as Kafka’s functional scope and level of abstraction are fundamentally different from ZeroMQ’s. However, it is a valid comparison from the perspective of the requirements of any problem at hand to inform a choice of one technology over the other. So let’s compare Kafka to ZeroMQ from the perspective of our problem of real-time log aggregation.
Topics and messages
When consolidating logs, it was important to us to partition logs into distinct logical streams. In our case we had two classes of streams: system-wide, administrative logs, and logs specific to a particular tenant running in our multi-tenant webtask environment.
Kafka has a first class notion of a topic, a key concept in many messaging systems. Topics can be published to and subscribed to, and are managed separately in terms of configuration and delivery guarantees. Kafka’s topics mapped very well onto our requirement to support distinct logical log streams.
ZeroMQ does not have a first class notion of a topic, yet it does have a first class concept of a subscription filter. Subscription filters let you decide which messages you are interested in receiving based on the prefix match on any otherwise opaque message. This feature combined with the support for multi-frame messages allowed us to easily and elegantly express the same semantics as Kafka topics in the context of our requirements. The first frame of every message contains the logical name of the stream, and the second frame the actual log record. We then configure ZeroMQ to do an exact match on the first frame so that we only receive the entries we care about.
Delivery guarantees
Kafka supports at-least-once delivery guarantees, ZeroMQ does not. ZeroMQ will drop messages if there are no subscribers listening (or subscribers fall behind) and the in-memory buffers of configurable size fill up.
While this lack of basic delivery guarantees would be a big no-no for some applications traditionally associated with message brokers, we felt it was a very pragmatic approach in the context of log consolidation, and a good trade off against overall complexity of the system required to support delivery guarantees. More on that in the Stability section below.
Durable state and performance
Kafka stores messages on disk in order to support its delivery guarantees, as well as the ability to go back in time - replay messages that had already been consumed. ZeroMQ only ever stores messages in limited in-memory buffers, and does not support replay.
As a result of this difference, despite Kafka being known to be super fast compared to other message brokers (e.g. RabbitMQ), it is necessarily slower than ZeroMQ given the need to go to disk and back.
Doing work always takes more effort than not doing it.
Since we’ve decided to scope out access to historical logs from the problem we were trying to solve and focus only on real-time log consolidation, that feature of Kafka became an unnecessary penalty without providing any benefits.
Stability
Stability was the key aspect of Kafka we were unhappy with after a yearlong journey with it.
An HA deployment of Kafka requires an HA deployment of zookeeper, which Kafka uses to coordinate distributed state and configuration. As I explained before, we’ve experienced a number of stability issues with this stateful cluster maintaining consistency through outages such as VM recycle. Some serious engineering time was going into reacting to issues, tracking them down, and subsequent stabilization attempts. Not to mention the cost that every downtime incurred.
With the transition to ZeroMQ, this entire layer of complexity was gone overnight. There are no moving parts to configure, deploy, manage, and support in our ZeroMQ design - all state is transient between in-memory data and the network.
Parts of the system that are not there never break.
What about access to historical logs?
With the problem of real-time log consolidation solved with ZeroMQ, supporting durable storage of logs for later post-processing becomes a smaller and a much more manageable challenge. For example, off the shelve solutions like Logstash are capable of capturing data from ZeroMQ and publishing it to a variety of destinations.
In our particular situation at Auth0, we are already using AWS Kinesis, ElasticSearch, and Kibana as a log processing pipeline in other parts of our operations. As such we are likely to develop a small, stateless message pump that will act as a ZeroMQ subscriber on one hand, and an AWS Kinesis client on the other to tap into this pipeline.
Conclusion
The move from Kafka to ZeroMQ for real-time log aggregation was the right choice to make in our circumstances. By focusing on the key requirements of our scenario we were able to significantly reduce the complexity of the solution. While improved stability and reliability was the key motivation for this transition, the added performance and reduced system complexity were a nice side effects.
As with any major change in a cloud service than needs to operate 24/7, more time needs to pass before we can fully understand the impact, in particular on stability. Bottom line is this: in the few days since we replaced Kafka with ZeroMQ the quality of my sleep has improved substantially.